这是SpringCloud实战系列中第7篇文章,了解前面第两篇文章更有助于更好理解本文内容: ①SpringCloud 实战:引入Eureka组件,完善服务治理 ②SpringCloud 实战:引入Feign组件,发起服务间调用 ③SpringCloud 实战:使用 Ribbon 客户端负载均衡 ④SpringCloud 实战:引入Hystrix组件,分布式系统容错 ⑤SpringCloud 实战:引入Zuul组件,开启网关路由 ⑥SpringCloud 实战:引入gateway组件,开启网关路由功能
背景
近年来,随着微服务架构的流行,很多公司都走上了微服务拆分之路。从而使系统变得越来越复杂,原本单体的系统被拆成很多个服务,每个服务之间通过轻量级的 HTTP 协议进行交互。
单体架构时,一个请求的调用链路非常清晰,一般由负载均衡器,比如 Nginx。将调用方的请求转发到后端服务,后端服务进行业务处理后返回给调用方。而当架构变成微服务架构时,可能带来一系列的问题,比如下面三个问题:
- 接口响应慢,怎么排查?
- 服务间的依赖关系如何查看?
- 请求贯穿多个微服务,如何将每个请求的日志串起来?
分布式链路跟踪
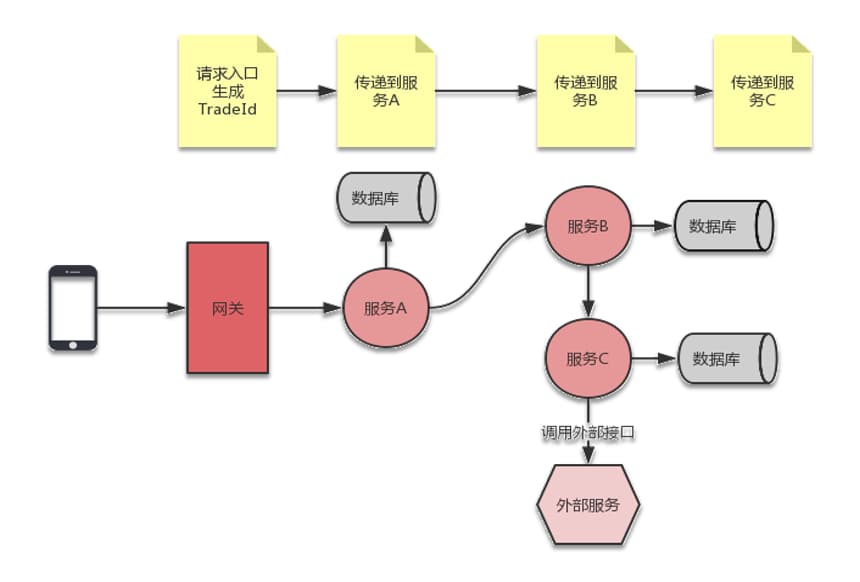
分布式链路跟踪原理在于如何能将请求经过的服务节点都关联起来。当一个请求从客户端到达网关后,相当于是第一个入口,这时就需要生成一个唯一的请求 ID,作为这次请求的标识。从网关到达服务 A 后,肯定是需要将请求 ID 传递到服务 A 中的,这样才能将网关到服务 A 的请求关联起来,依次类推,后面会经过多层服务,都需要将信息一层层传递。当然在每一层都需要将数据进行上报、统一存储、展示等操作。
从我们对这个需求的理解来看,链路跟踪并不是很复杂,而复杂的点在于如何实现这一套跟踪框架,就拿请求信息传递这件事来说,服务之间交互,有的用的是 Feign 调用接口,有的用的是 RestTemplate 调用接口,要想将信息传递到下游服务,那么必须得扩展这些调用的框架才可以。
核心概念
-
Span
基本工作单元,例如,发送 RPC 请求是一个新的 Span,发送 HTTP 请求是一个新的 Span,内部方法调用也是一个新的 Span。
-
Trace
一次分布式调用的链路信息,每次调用链路信息都会在请求入口处生成一个
TraceId。 -
Annotation
用于记录事件的信息。在 Annotation 中会有 CS、SR、SS、CR 这些信息,前面的C表示客户端,S表示服务器端; 后面的S表示sent,也就是发起请求时的动作,R表示Received,也就是接受到请求时的动作;下面分别介绍下这些信息的作用。
- CS
也就是
Client Sent,客户端发起一个请求,这个 Annotation 表示 Span 的开始。 - CR
也就是
Client Received,表示 Span 的结束,客户端已成功从服务器端收到响应,用 CR 的时间戳减去 CS 的时间戳就可以知道客户端从服务器接收响应所需的全部时间。 - SS
也就是
Server Sent,在请求处理完成时将响应发送回客户端,用 SS 的间戳减去 SR 的时间戳会显示服务器端处理请求所需的时间。 - SR
也就是
Server Received,服务器端获得请求并开始处理它,用 SR 的时间戳减去 CS 的时间戳会显示网络延迟时间。
- CS
也就是
请求追踪过程分解
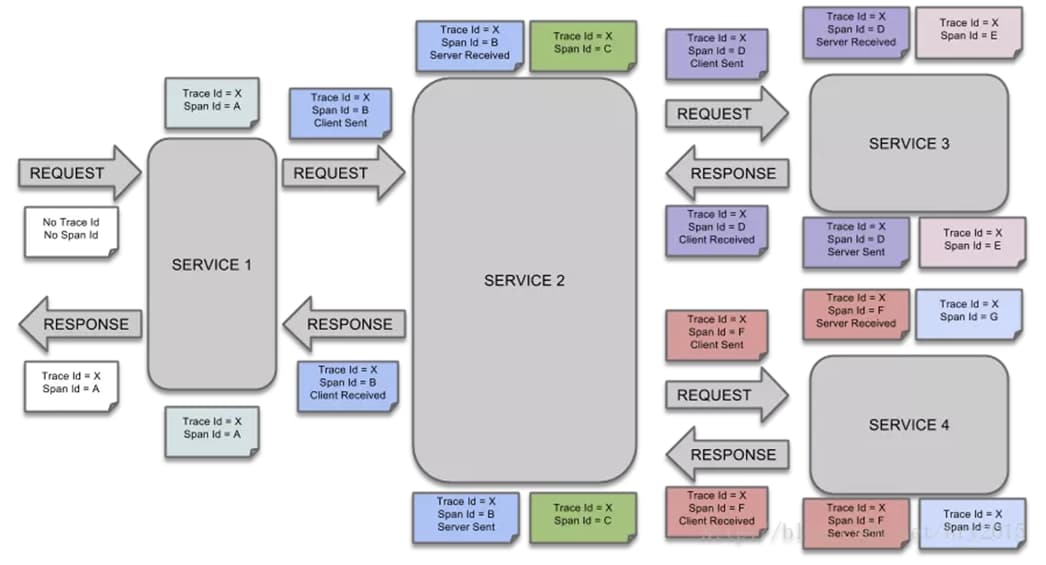
- 首先当一个请求访问 SERVICE1 时,这时是没有 Trace 和 Span 的,然后会生成 Trace 和 Span,如图所示生成的 Trace ID 是 X,Span ID 是 A。
- 接着 SERVICE1 请求 SERVICE2,这是一次远程请求,会生成一个新的 Span,Span ID 为 B,Trace ID 不变还是 X。Span B 处于 CS 状态。
- 当请求到达 SERVICE2 后,Trade ID 和 Span ID 就被传递过来了,这时,SERVICE2 有内部操作,又生成了一个新的 Span,Span ID 为 C,Trace ID 不变还是 X。
- SERVICE2 处理完后向 SERVICE3 发起请求,同时产生新的 Span,Span ID 为 D,Span D 处于 CS 状态,SERVICE3 接收到请求后,Span D 处于 SR 状态,同时 SERVICE3 内部操作也会产生新的 Span,Span ID 为 E。
- 当 SERVICE3 处理完后,需要将结果响应给调用方,这时 Span D 就处于 SS 的状态,当 SERVICE2 收到响应后,Span ID 为 D 的 Span 就是 CR 状态,表示 Span 已经结束了。
Zipkin 介绍
Zipkin 是 Twitter 的一个开源项目,是一个致力于收集所有服务监控数据的分布式跟踪系统,它提供了收集数据和查询数据两大接口服务。有了 Zipkin 我们就可以很直观地查看调用链,并且可能很方便看出服务之间的调用关系,以及调用耗费的时间。
Zipkin还提供了可插拔数据存储方式:In-Memory、MySql、Cassandra以及Elasticsearch。测试方便可直接采用In-Memory方式进行存储,生产推荐使用Elasticsearch。
安装 Zipkin
如果使用了 Java 8 或者更高的版本,可以获取最新的可执行 jar 包来进行启动。
-
下载jar包:
curl -sSL https://zipkin.io/quickstart.sh | bash -s如果下载太慢,可以直接访问Maven地址进行下载最新的jar。
其他方式安装,可以查看官网的quickstart。
-
启动服务
java -jar zipkin.jar -
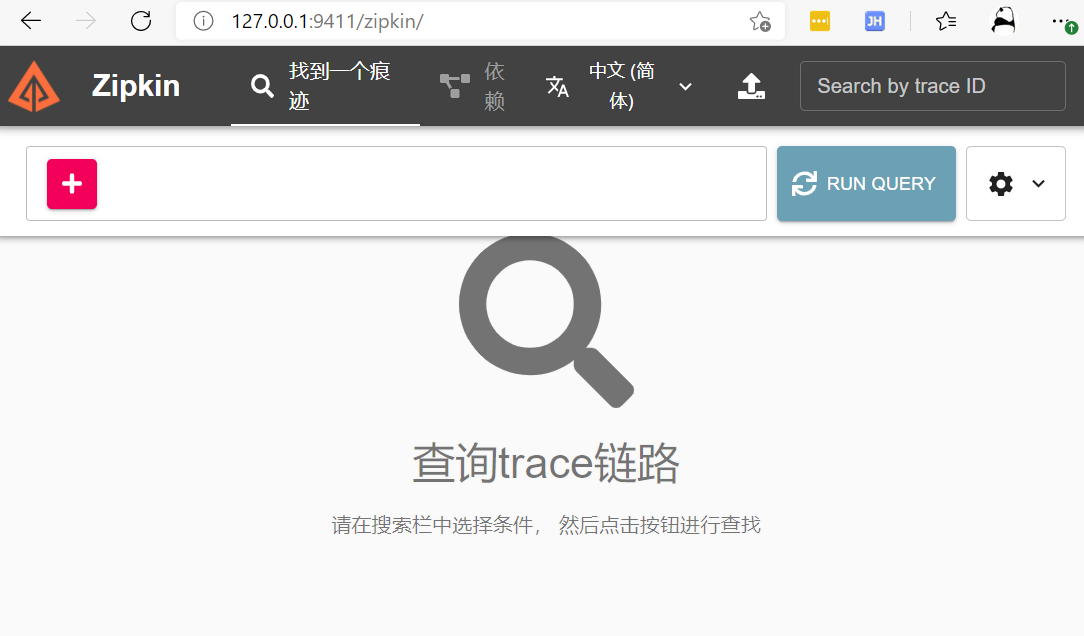
访问Zipkin
成功启动服务后,访问http://127.0.0.1:9411/zipkin/即可。
Sleuth 介绍
Spring Cloud Sleuth 是一种分布式的服务链路跟踪解决方案,通过使用 Spring Cloud Sleuth 可以让我们快速定位某个服务的问题,以及厘清服务间的依赖关系。
Sleuth 可以添加链路信息到日志中,这样的好处是可以统一将日志进行收集展示,并且可以根据链路的信息将日志进行串联。
Sleuth 中的链路数据可直接上报给 Zipkin,在 Zipkin 中就可以直接查看调用关系和每个服务的耗时情况.
Sleuth 中内置了很多框架的埋点,比如:Zuul、Feign、Hystrix、RestTemplate 等。正因为有了这些框架的埋点,链路信息才能一直往下传递。
通过 Http 结合Zipkin
-
在我们的微服务项目中添加Zipkin依赖
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency> -
配置Zipkin地址
spring.zipkin.base-url=http://127.0.0.1:9411/ -
配置采样比例 实际使用中可能调用了 10 次接口,但是 Zipkin 中只有一条数据,这是因为收集信息是有一定比例的,Zipkin 中的数据条数与调用接口次数默认比例是 10:1,通过下面的配置来改变这个比例值:
```xml spring.sleuth.sampler.probability=1.0 ``` -
验证 启动我们的微服务,访问 http://localhost:9000/eureka-client/sayHello 接口,接口由网关路由到eureka-client 服务,eureka-client 服务再调用eureka-provider服务,接口返回eureka-provider服务的端口等信息。 然后访问 http://127.0.0.1:9411/zipkin ,点击查询,即可查看到相关访问记录
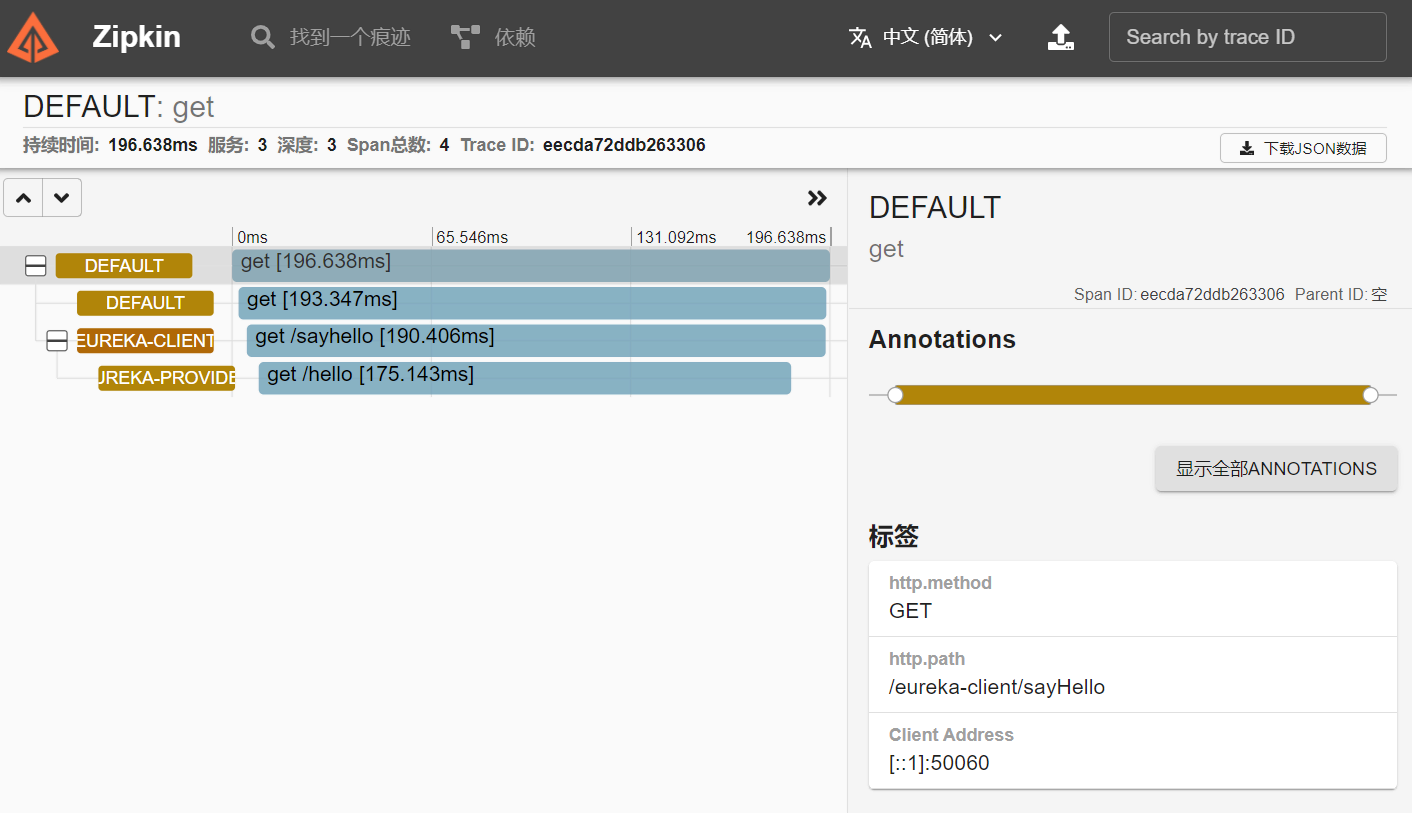
点击菜单上面的依赖,可以查看项目的依赖关系 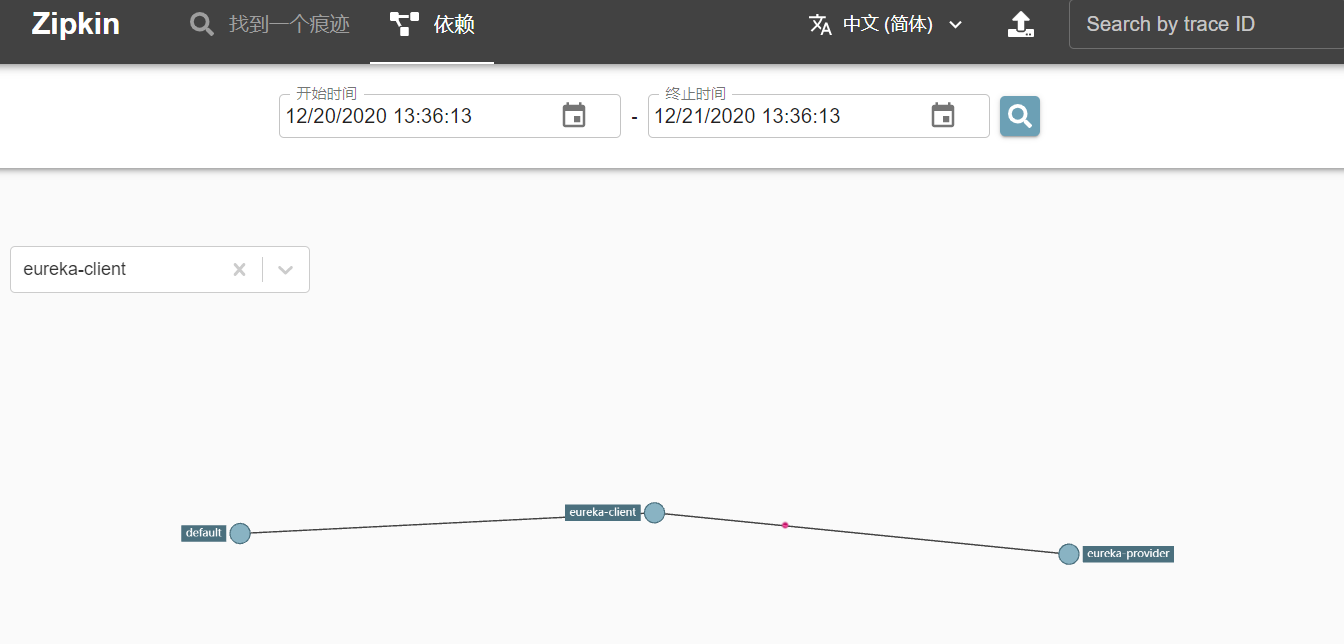
使用 RabbitMQ or Kafka 代替 HTTP 发送调用链数据
数据的发送如果采用 HTTP 对性能还是有影响的。如果Zipkin 的服务端在重启或者挂掉时,那么将丢失部分采集数据。为了解决这些问题,我们可以集成 RabbitMQ 或者Kafka 来发送采集数据,利用消息队列来提高发送性能,保证数据不丢失;
-
如果要使用RabbitMQ或Kafka而不是HTTP,需要引入
spring-rabbitorspring-kafka相关依赖。<dependency> <groupId>org.springframework.amqp</groupId> <artifactId>spring-rabbit</artifactId> </dependency> -
然后在配置文件修改相关配置:
# WEB、KAFKA、RABBIT、ACTIVEMQ spring.zipkin.sender.type=kafka -
删除之前配置的 spring.zipkin.base-url
-
配置kafka、rabbit
自定义 Zipkin 配置
每个跟踪系统都需要具有Reporter <Span>和Sender,如果要覆盖提供的bean,则需要给它们指定一个特定的名称 ZipkinAutoConfiguration.REPORTER_BEAN_NAME and ZipkinAutoConfiguration.SENDER_BEAN_NAME。
下面是示例:
@Configuration
protected static class MyConfig {
@Bean(ZipkinAutoConfiguration.REPORTER_BEAN_NAME)
Reporter<zipkin2.Span> myReporter() {
return AsyncReporter.create(mySender());
}
@Bean(ZipkinAutoConfiguration.SENDER_BEAN_NAME)
MySender mySender() {
return new MySender();
}
static class MySender extends Sender {
private boolean spanSent = false;
boolean isSpanSent() {
return this.spanSent;
}
@Override
public Encoding encoding() {
return Encoding.JSON;
}
@Override
public int messageMaxBytes() {
return Integer.MAX_VALUE;
}
@Override
public int messageSizeInBytes(List<byte[]> encodedSpans) {
return encoding().listSizeInBytes(encodedSpans);
}
@Override
public Call<Void> sendSpans(List<byte[]> encodedSpans) {
this.spanSent = true;
return Call.create(null);
}
}
}