简介
Phaser 是 JDK 1.7 开始提供的一个可重复使用的同步屏障,功能类似于CyclicBarrier和CountDownLatch,但使用更灵活,支持对任务的动态调整,并支持分层结构来达到更高的吞吐量。
Registration(注册)
与其他屏障的情况不同,在 Phaser 上注册同步的参与方的数量可能随时间而变化。任务可以在任何时候注册(使用方法register、bulkRegister或建立初始参与方数量的构造函数),可以在任何到达时取消注册(使用arriveAndDeregister),注册和注销只影响内部计数,任务无法查询它们是否已注册。
Synchronization(同步)
像CyclicBarrier,Phaser也可以重复await。方法arriveAndAwaitAdvance()有效果类似于CyclicBarrier.await 。phaser的每一代都有一个相关的phase number,初始值为0,当所有注册的任务都到达phaser时phase+1,到达最大值(Integer.MAX_VALUE)之后清零。使用phase number可以独立控制到达phaser 和 等待其他线程 的动作,通过下面两种类型的方法:
- Arrival(到达机制)
arrive和arriveAndDeregister方法记录到达状态。 这些方法不会阻塞,但是会返回一个相关的arrival phase number;也就是说,phase number用来确定到达状态。当所有任务都到达给定phase时,可以执行一个可选的函数,这个函数通过重写onAdvance方法实现,通常可以用来控制终止状态。 重写此方法类似于为CyclicBarrier提供一个barrierAction(执行的命令线程),但比它更灵活。 - Waiting(等待机制)
awaitAdvance方法需要一个表示 arrival phase number 的参数,并且在phaser前进到与给定phase不同的phase时返回。和CyclicBarrier不同,即使等待线程已经被中断,awaitAdvance方法也会一直等待。中断状态和超时时间同样可用,但是当任务等待中断或超时后未改变phaser的状态时会遭遇异常。如果有必要,在方法forceTermination之后可以执行这些异常的相关的handler进行恢复操作,Phaser也可能被ForkJoinPool中的任务使用,这样在其他任务阻塞等待一个phase时可以保证足够的并行度来执行任务。
Termination(终止机制)
可以用isTerminated方法检查phaser的终止状态。
在终止时,所有同步方法立刻返回一个负值。
在终止时尝试注册也没有效果。当调用onAdvance返回true时Termination被触发。当deregistration操作使已注册的parties变为0时,onAdvance的默认实现就会返回true。也可以重写onAdvance方法来定义终止动作。forceTermination方法也可以释放等待线程并且允许它们终止。
Tiering(分层结构)
Phaser支持分层结构(树状构造)来减少竞争。
注册了大量parties的Phaser可能会因为同步竞争消耗很高的成本, 因此可以设置一些子Phaser来共享一个通用的parent。这样的话即使每个操作消耗了更多的开销,但是会提高整体吞吐量。 在一个分层结构的phaser里,子节点phaser的注册和取消注册都通过父节点管理。
子节点phaser通过构造或方法register、bulkRegister进行首次注册时,在其父节点上注册。子节点phaser通过调用arriveAndDeregister进行最后一次取消注册时,也在其父节点上取消注册。
Monitoring(状态监控)
由于同步方法可能只被已注册的parties调用,所以phaser的当前状态也可能被任何调用者监控。在任何时候,可以通过getRegisteredParties获取parties数,其中getArrivedParties方法返回已经到达当前phase的parties数。当剩余的parties(通过方法getUnarrivedParties获取)到达时,phase进入下一代。这些方法返回的值可能只表示短暂的状态,所以一般来说在同步结构里并没有啥卵用。
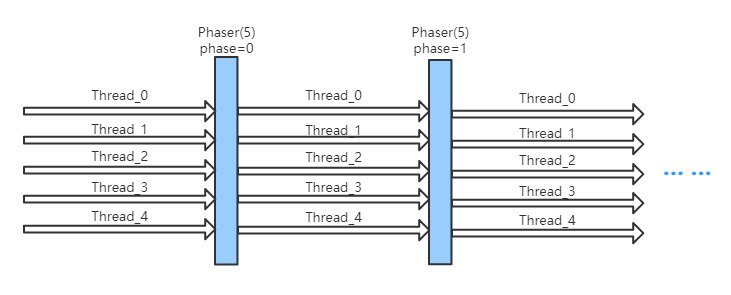
分层运行示意图
使用示例
void runTasks(List<Runnable> tasks) throws InterruptedException{
// "1" to register self
final Phaser phaser = new Phaser(1);
// create and start threads
for (final Runnable task : tasks) {
phaser.register();
new Thread() {
@Override
public void run() {
// await all creation jingling.im
// 类似 CountDownLatch.await() 和 CyclicBarrier.await()
System.out.println("等待所有的任务+1");
phaser.arriveAndAwaitAdvance();
task.run();
}
}.start();
}
// allow threads to start and deregister self
TimeUnit.SECONDS.sleep(1);
System.out.println("jingling.im 放行。。。。。。");
// 类似 CountDownLatch.countDown() 减到了0 和 CyclicBarrier 中的最后一个线程调用了await()
phaser.arriveAndDeregister();
}多阶段运行示例
这里的阶段有点类似多次使用CyclicBarrier,并不是Phaser的分层
void runTasks2() {
// 定义阶段数
int phases = 3;
// 进入下一个阶段需要的参与数(线程数)
int parties = 5;
// 自定义onAdvance https://jingling.im
Phaser phaser = new Phaser(parties){
@Override
protected boolean onAdvance(int phase,int registeredParties){
System.out.println("阶段phase: "+(phase +1) +" 执行完毕");
return phase > phases || registeredParties == 0;
}
};
for(int i = 1; i <= parties; i++){
new Thread(()->{
for(int j = 1; j <= phases; j++){
System.out.println(Thread.currentThread().getName() + " doing 阶段:"+ j);
phaser.arriveAndAwaitAdvance();
}
},"Thread-"+i).start();
}
}运行结果:
Thread-1 doing 阶段:1
Thread-4 doing 阶段:1
Thread-3 doing 阶段:1
Thread-2 doing 阶段:1
Thread-5 doing 阶段:1
阶段phase: 1 执行完毕
Thread-5 doing 阶段:2
Thread-3 doing 阶段:2
Thread-4 doing 阶段:2
Thread-1 doing 阶段:2
Thread-2 doing 阶段:2
阶段phase: 2 执行完毕
Thread-2 doing 阶段:3
Thread-3 doing 阶段:3
Thread-1 doing 阶段:3
Thread-4 doing 阶段:3
Thread-5 doing 阶段:3
阶段phase: 3 执行完毕 jingling.im源码分析
内部类QNode
内部等待队列,用于在阻塞时记录等待线程及相关信息
static final class QNode implements ForkJoinPool.ManagedBlocker {
final Phaser phaser;
final int phase;
final boolean interruptible;
final boolean timed;
boolean wasInterrupted;
long nanos;
final long deadline;
volatile Thread thread; // nulled to cancel wait
QNode next; // 由此看出是一个单向列表
QNode(Phaser phaser, int phase, boolean interruptible,
boolean timed, long nanos) {
this.phaser = phaser;
this.phase = phase;
this.interruptible = interruptible;
this.nanos = nanos;
this.timed = timed;
this.deadline = timed ? System.nanoTime() + nanos : 0L;
thread = Thread.currentThread();
}
... 部分代码省略 ...
}主要的属性
// 状态变量,用于存储当前阶段phase、参与者数parties、未完成的参与者数unarrived_count
// 低0-15位表示未到达parties数,中16-31位表示等待的parties数,中32-62位表示当前阶段phase
private volatile long state;
// 最多可以有多少个参与者,即每个阶段最多有多少个任务,十进制表示为65535
private static final int MAX_PARTIES = 0xffff;
// 最多可以有多少阶段,2的31次方-1,十进制:2147483647
private static final int MAX_PHASE = Integer.MAX_VALUE;
// 参与者数量的偏移量
private static final int PARTIES_SHIFT = 16;
// 阶段的偏移量
private static final int PHASE_SHIFT = 32;
// 未完成的参与者数的掩码,低16位,二进制:1111 1111 1111 1111
private static final int UNARRIVED_MASK = 0xffff; // to mask ints
// 参与者数,中间16位,二进制:1111 1111 1111 1111 0000 0000 0000 0000
private static final long PARTIES_MASK = 0xffff0000L; // to mask longs
// counts的掩码,counts等于参与者数和未完成的参与者数的'|'操作
// 二进制:1111 1111 1111 1111 1111 1111 1111 1111
private static final long COUNTS_MASK = 0xffffffffL;
// 二进制位第64位为1,终止位
private static final long TERMINATION_BIT = 1L << 63;
// 一些特殊的值
// 一次一个参与者完成
private static final int ONE_ARRIVAL = 1;
// 增加减少参与者时使用,1左移16位,二进制:0001 0000 0000 0000 0000
private static final int ONE_PARTY = 1 << PARTIES_SHIFT;
// 减少参与者时使用,二进制:0001 0000 0000 0000 0001
private static final int ONE_DEREGISTER = ONE_ARRIVAL|ONE_PARTY;
// 没有参与者时使用
private static final int EMPTY = 1;
// 当前Phaser的父级;如果没有,则为null
private final Phaser parent;
/** phaser的根。如果不在树中则等于phaser */
private final Phaser root;
/** 两个队列链表,在偶数和奇数阶段交替使用 */
private final AtomicReference<QNode> evenQ; // 偶数
private final AtomicReference<QNode> oddQ; // 奇数构造方法
public Phaser() {
this(null, 0);
}
public Phaser(int parties) {
this(null, parties);
}
public Phaser(Phaser parent) {
this(parent, 0);
}
public Phaser(Phaser parent, int parties) {
if (parties >>> PARTIES_SHIFT != 0)
throw new IllegalArgumentException("Illegal number of parties");
int phase = 0;
this.parent = parent;
if (parent != null) { // 有设置parent jingling.im
final Phaser root = parent.root;
this.root = root;
this.evenQ = root.evenQ;
this.oddQ = root.oddQ;
if (parties != 0)
phase = parent.doRegister(1);
}
else {
this.root = this; // root是当前phaser
// 初始化两个队列
this.evenQ = new AtomicReference<QNode>();
this.oddQ = new AtomicReference<QNode>();
}
// 确定state,先是一个三目运算
// parties 为 0 时,state为 1
//
this.state = (parties == 0) ? (long)EMPTY :
((long)phase << PHASE_SHIFT) | // 当前阶段左移32位
((long)parties << PARTIES_SHIFT) | // 等待的parties数,左移16位
((long)parties); // 未到达parties数,就存低16位
}整个构造方法最重要的就是最后state值的确认,也可以看出低0-15位表示未到达parties数,中16-31位表示等待的parties数,中32-62位表示当前阶段phase。
比如入参为5的话,初始化的state值的二进制表示为:0101 0000 0000 0000 0101
register()方法
方法说明:向当前phaser添加一个新的unarrived(未到达)的party,如果onAdvance正在运行,那么这个方法会等待它运行结束再返回结果。如果当前phaser有父节点,并且当前phaser上没有已注册的party,那么就会交给父节点注册。
代码分析:
public int register() {
return doRegister(1);
}
private int doRegister(int registrations) {
// 调整的状态,等待的parties数和unarrived(未到达)parties数同时增加
long adjust = ((long)registrations << PARTIES_SHIFT) | registrations;
final Phaser parent = this.parent;
int phase;
for (;;) { //自旋
long s = (parent == null) ? state : reconcileState(); // 取state值
// 转换成int,state的低32位,也就是parties和unarrived的值
int counts = (int)s;
// 取等待的parties数
int parties = counts >>> PARTIES_SHIFT;
// UNARRIVED_MASK,低16位,二进制:1111 1111 1111 1111
// 也就是取低16中存的未到达数parties数
int unarrived = counts & UNARRIVED_MASK;
// 1 > 65535 - parties
if (registrations > MAX_PARTIES - parties) // 检查容量
throw new IllegalStateException(badRegister(s));
phase = (int)(s >>> PHASE_SHIFT); // 无符号右移32位,取出当前的阶段phase
if (phase < 0)
break; // 退出自旋,返回phase ,也就是负数
// 不是第一个参与者
if (counts != EMPTY) { // not 1st registration
if (parent == null || reconcileState() == s) {
if (unarrived == 0)// unarrived等于0说明当前阶段正在执行onAdvance()方法,等待advance方法退出
root.internalAwaitAdvance(phase, null); // 阻塞并等待阶段前进
else if (UNSAFE.compareAndSwapLong(this, stateOffset, s, s + adjust))
// 使用CAS的方式修改state值,增加adjust,成功的话退出自旋,返回phase
break;
}
} else if (parent == null) {// 没有设置父节点
// 计算state的值
long next = ((long)phase << PHASE_SHIFT) | adjust;
if (UNSAFE.compareAndSwapLong(this, stateOffset, s, next))
// CAS 修改成功则退出自旋
break;
} else { //以上两种情况都不是,有多层级的时候
synchronized (this) { // 1st sub registration
if (state == s) { // recheck under lock
phase = parent.doRegister(1); // 交给父节点完成注册
if (phase < 0)
break; //退出自旋,返回phase ,也就是负数
// 走到这儿,说明父节点注册成功了(phase大于0),while自旋,直到CAS修改成功
while (!UNSAFE.compareAndSwapLong(this, stateOffset, s,((long)phase << PHASE_SHIFT) | adjust)) {
s = state;
phase = (int)(root.state >>> PHASE_SHIFT);
// assert (int)s == EMPTY; jingling.im
}
break;
}
}
}
}
return phase;
}reconcileState()方法
子Phaser的phase在没有被真正使用之前,允许滞后于它的root节点。非首次注册时,如果Phaser有父节点,则调用reconcileState()方法解决root节点的phase延迟传递问题.
当root节点的phase已经advance到下一代,但是子节点phaser还没有,这种情况下它们必须通过更新未到达parties数 完成它们自己的advance操作(如果parties为0,重置为EMPTY状态)。
private long reconcileState() {
final Phaser root = this.root;
long s = state;
if (root != this) {
int phase, p;
// CAS to root phase with current parties, tripping unarrived
while ((phase = (int)(root.state >>> PHASE_SHIFT)) !=
(int)(s >>> PHASE_SHIFT) &&
!UNSAFE.compareAndSwapLong(this, stateOffset, s,
s = (((long)phase << PHASE_SHIFT) |
((phase < 0) ? (s & COUNTS_MASK) :
(((p = (int)s >>> PARTIES_SHIFT) == 0) ? EMPTY :
((s & PARTIES_MASK) | p))))))
s = state;
}
return s;
}internalAwaitAdvance()方法:
除非终止,否则可能会阻塞或等待phase前进到下一代
private int internalAwaitAdvance(int phase, QNode node) {
// assert root == this;
// 确保旧队列是干净的
releaseWaiters(phase-1); // ensure old queue clean
// 入队成功变为true
boolean queued = false; // true when node is enqueued
int lastUnarrived = 0; // to increase spins upon change
int spins = SPINS_PER_ARRIVAL; //自旋的次数,(NCPU < 2) ? 1 : 1 << 8;1或者256次
long s;
int p;
while ((p = (int)((s = state) >>> PHASE_SHIFT)) == phase) { // 无符号右移32位,得到当前阶段,检查是否有变化
if (node == null) { // spinning in noninterruptible mode
int unarrived = (int)s & UNARRIVED_MASK; // 与掩码计算,得到低16位代表的未到达数
// 未到达数有变化且小于CPU核数
if (unarrived != lastUnarrived && (lastUnarrived = unarrived) < NCPU)
spins += SPINS_PER_ARRIVAL; // 增加自旋次数
boolean interrupted = Thread.interrupted(); // 线程中断
if (interrupted || --spins < 0) { // need node to record intr
// 线程被中断了或者自旋次数小于0,需要节点记录索引
node = new QNode(this, phase, false, false, 0L);
node.wasInterrupted = interrupted;
}
}else if (node.isReleasable()) // done or aborted
break; // 完成或者终止,退出自旋
else if (!queued) { // 推入队列
// (phase & 1 == 0 )通过位运算快速判断是奇偶数
AtomicReference<QNode> head = (phase & 1) == 0 ? evenQ : oddQ;
QNode q = node.next = head.get();
// 再次判断
if ((q == null || q.phase == phase) && (int)(state >>> PHASE_SHIFT) == phase) // avoid stale enq
queued = head.compareAndSet(q, node); // CAS修改入队
} else {
try {
ForkJoinPool.managedBlock(node); // 阻塞node,等待被唤醒
} catch (InterruptedException ie) {
node.wasInterrupted = true;
}
}
}
// 线程已经被唤醒,并且phase已经有变化了才会退出上面的自旋,或者完成终止,退出自旋 jingling.im
if (node != null) {
if (node.thread != null)
node.thread = null; // 避免 unpark()
if (node.wasInterrupted && !node.interruptible)
Thread.currentThread().interrupt();
if (p == phase && (p = (int)(state >>> PHASE_SHIFT)) == phase)
return abortWait(phase); // possibly clean up on abort
}
// 唤醒当前phaser阶段的线程
releaseWaiters(phase);
return p;
}
/** 从队列中删除线程,唤醒当前phaser阶段的线程 */
private void releaseWaiters(int phase) {
QNode q; // 队列的第一个元素
Thread t; // its thread
// 再次根据当前phaser选择对应的队列
AtomicReference<QNode> head = (phase & 1) == 0 ? evenQ : oddQ;
while ((q = head.get()) != null && q.phase != (int)(root.state >>> PHASE_SHIFT)) {
if (head.compareAndSet(q, q.next) && (t = q.thread) != null) {
// 删掉q节点,唤醒q节点中的线程
q.thread = null;
LockSupport.unpark(t); // 唤醒线程
}
}
}register()方法总结:
- register方法为phaser添加一个新的party,如果onAdvance正在运行,那么这个方法会等待它运行结束再返回结果。
- register和bulkRegister都由doRegister实现,bulkRegister是批量注册添加
- 使用了自旋 + CAS 技术来保证更新成功
- 如果前阶段正在执行onAdvance()方法,则需要阻塞等待(根据phase入相应队列)其执行完后再进行注册
- 当前phaser如果有父节点,需要交由父节点来完成注册
arrive()方法
使当前线程到达phaser,不等待其他任务到达。返回arrival phase number。
public int arrive() {
// 一次一个参与者完成
return doArrive(ONE_ARRIVAL); // 特殊的属性值 ONE_ARRIVAL: 1
}
private int doArrive(int adjust) {
final Phaser root = this.root;
for (;;) { // 自旋
long s = (root == this) ? state : reconcileState(); // 确定state值
int phase = (int)(s >>> PHASE_SHIFT); //位运算,得到当前阶段phaser
if (phase < 0)
return phase;
int counts = (int)s; // 表示parties和unarrived的值
int unarrived = (counts == EMPTY) ? 0 : (counts & UNARRIVED_MASK); // 计算未到达数
if (unarrived <= 0)
throw new IllegalStateException(badArrive(s)); // 到达时边界异常
if (UNSAFE.compareAndSwapLong(this, stateOffset, s, s-=adjust)) { // CAS直接修改state
if (unarrived == 1) { // == 1 表示当前为最后一个未到达的任务
long n = s & PARTIES_MASK; // 掩码计算当前parties, 保留了16-32位的部分
int nextUnarrived = (int)n >>> PARTIES_SHIFT;
if (root == this) {
if (onAdvance(phase, nextUnarrived))// 判断 registeredParties == 0,返回true,需要终止phaser
n |= TERMINATION_BIT; // 标识终止位
else if (nextUnarrived == 0)
n |= EMPTY;
else
n |= nextUnarrived;
int nextPhase = (phase + 1) & MAX_PHASE; // 下一个阶段phaser
n |= (long)nextPhase << PHASE_SHIFT; // 下一个阶段phaser左移32位再加上当前的phaser就是最新的phaser
UNSAFE.compareAndSwapLong(this, stateOffset, s, n); //CAS 修改
releaseWaiters(phase); // 释放等待phase的线程
} else if (nextUnarrived == 0) { // propagate deregistration
phase = parent.doArrive(ONE_DEREGISTER); // 使用父节点管理
UNSAFE.compareAndSwapLong(this, stateOffset, s, s | EMPTY);
} else
phase = parent.doArrive(ONE_ARRIVAL); // 使用父节点管理
}
// 不是最后一个到达,直接返回phaser
return phase;
}
}
}arrive()方法总结:
- 通过位运算计算当前state、phaser等值
- 然后直接使用自旋+CAS更新state值(
state-=adjust) - 如果当前不是最后一个未到达的任务,直接返回当前phaser值
- 如果当前是最后一个未到达的任务
- 如果当前是root节点,判断是否需要终止phase(
nextUnarrived == 0)r,然后CAS更新state,最后释放等待phase的线程 - 如果是分层结构,并且已经没有下一代未到达的parties,则交由父节点处理doArrive逻辑,然后更新state为
EMPTY
- 如果当前是root节点,判断是否需要终止phase(
arriveAndDeregister()方法
使当前线程到达phaser并撤销注册,返回arrival phase number。
arriveAndDeregister()方法和arrive()方法非常类似,都是调用的doArrive()方法,只是入参有些区别,arriveAndDeregister()方法传入的入参是ONE_DEREGISTER,同时减参与者和未到达者。
arriveAndAwaitAdvance()方法
到达并等待其他人到达
public int arriveAndAwaitAdvance() {
// Specialization of doArrive+awaitAdvance eliminating some reads/paths
final Phaser root = this.root;
for (;;) { // 自旋
// 当前state值
long s = (root == this) ? state : reconcileState();
int phase = (int)(s >>> PHASE_SHIFT); // 位运算-->当前阶段
if (phase < 0) // onAdvance()方法返回true后,中断位标识后phase就会小于0
return phase;
int counts = (int)s; // =>int
// 未到达数
int unarrived = (counts == EMPTY) ? 0 : (counts & UNARRIVED_MASK);
if (unarrived <= 0)
throw new IllegalStateException(badArrive(s)); // 到达时边界异常
// CAS 修改state值 s-=1
if (UNSAFE.compareAndSwapLong(this, stateOffset, s, s -= ONE_ARRIVAL)) {
if (unarrived > 1) // 还是超过1个未到达,加入队列阻塞等待
return root.internalAwaitAdvance(phase, null);
// 到下面这里,说明是最后一个到达
if (root != this) // root 不是当前自己,交由父节点阻塞等待
return parent.arriveAndAwaitAdvance();
// 位运算,得到parties,s是CAS计算过后的值,
long n = s & PARTIES_MASK; // base of next state
// 即下一次需要到达的参与者数量
int nextUnarrived = (int)n >>> PARTIES_SHIFT;
if (onAdvance(phase, nextUnarrived)) // 判断是否要终止,nextUnarrived == 0
n |= TERMINATION_BIT; // 标识终止位
else if (nextUnarrived == 0)
n |= EMPTY;
else
n |= nextUnarrived; // n 加上unarrived的值,下个阶段
int nextPhase = (phase + 1) & MAX_PHASE; // +1,进入下一个阶段
n |= (long)nextPhase << PHASE_SHIFT; // 标识到具体的位
if (!UNSAFE.compareAndSwapLong(this, stateOffset, s, n)) // CAS 修改
return (int)(state >>> PHASE_SHIFT); // terminated
releaseWaiters(phase); // 唤醒当前阶段的线程,可以进行下一段了
return nextPhase; //返回下一阶段
}
}
}arriveAndAwaitAdvance()方法总结:
- 主要逻辑就是自旋+CAS 修改state中低16的unarrived的值-1,知道自旋修改成功
- 如果调用当前的线程不是最后一个到达,需要入队阻塞等待
- 如果是最后一个到达的线程,则调用
onAdvance()方法,返回true表示需要被中断,之后的phase就会小于0,再次调用arriveAndAwaitAdvance()方法也就么有阻塞等待效果了 onAdvance()方法支持重写,我们可以自定义判断规则
awaitAdvance()方法
等待指定phase数,返回下一个 arrival phase number。
public int awaitAdvance(int phase) {
final Phaser root = this.root;
long s = (root == this) ? state : reconcileState();
int p = (int)(s >>> PHASE_SHIFT); // 当前阶段
if (phase < 0)
return phase;
if (p == phase)
// 阻塞或等待phase前进到下一代,internalAwaitAdvance见上面代码分析
return root.internalAwaitAdvance(phase, null);
return p;
}Phaser 总结
- Phaser 使用了state变量来维护各个逻辑状态的计数
- state的低0-15位表示未到达parties数,中16-31位表示等待的parties数,中32-62位表示当前阶段phase,第64位为终止位
- 维护的QNode队列根据当前阶段的奇偶性来选择,判断奇偶性可以使用
(phase & 1) == 0来快速判断 - 每个阶段最后一个参与者到达时,会唤醒队列中的线程进入到下一阶段,不是最后一个参与者到达会阻塞等待
- 重写onAdvance方法可以达到CyclicBarrier的barrierAction类似效果,即在阶段完成执行指定的命令
与CyclicBarrier和CountDownLatch比较灵活在那里?
- Phaser 支持分层,支持多个阶段,功能更加丰富与灵活
- 可以使用register方法追加参与者
- 也可以使用arriveAndDeregister方法到达但是不用等待
- CountDownLatch 不支持循环使用,只能控制一个或一组线程
- CyclicBarrier 支持循环使用,但不支持分层,不支持修改任务数