什么是I/O
I/O(英语:Input/Output),即输入/输出,通常指数据在存储器(内部和外部)或其他周边设备之间的输入和输出,是信息处理系统(例如计算机)与外部世界(可能是人类或另一信息处理系统)之间的通信。输入是系统接收的信号或数据,输出则是从其发送的信号或数据。 ——维基百科I/O
Java IO分类
按传输方式
从传输方式上,一般可以分为字符流和字节流;字节流一般读取单个字节,字符流读取单个字符;
可以理解字节是给计算机看的,字符是给人看的。
常见的字节流有:
InputStreamOutputStream
常见的字符流有:
ReaderWriter
按数据来源
从数据来源的角度看IO, 可以有以下几类:
-
文件(file)
FileInputStream、FileOutputStream、FileReader、FileWriter -
数组([])
字节数组(byte[]):
ByteArrayInputStream、ByteArrayOutputStream字符数组(char[]):
CharArrayReader、CharArrayWriter -
管道操作
PipedInputStream、PipedOutputStream、PipedReader、PipedWriter -
基本数据类型
DataInputStream、DataOutputStream -
缓冲操作
BufferedInputStream、BufferedOutputStream、BufferedReader、BufferedWriter -
打印
PrintStream、PrintWriter -
对象序列化反序列化
ObjectInputStream、ObjectOutputStream -
转换
InputStreamReader、OutputStreamWriter
InputStream
InputStream 是一个抽象类,主要提供了一个数据输入读取相关的抽象方法。
public abstract int read() throws IOException;还有一些其他覆盖的方法:
// 将读取到的数据放在 byte 数组中,该方法实际上是根据下面的方法实现的,off 为 0,len 为数组的长度
public int read(byte b[]){...}
// 从第 off 位置读取 len 长度字节的数据放到 byte 数组中,流是以 **-1** 来判断是否读取结束的
public int read(byte b[], int off, int len){...}
**// 跳过指定个数的字节不读取,想想看电影跳过片头片尾
public long skip(long n){...}
// 返回可读的字节数量,默认0
public int available(){...}
// 读取完,关闭流,释放资源, 需要自己实现
public void close(){...}
// 标记读取位置,下次还可以从这里开始读取,使用前要看当前流是否支持,可以使用 markSupport() 方法判断
public synchronized void mark(int readlimit){}
// 重置读取位置为上次 mark 标记的位置(默认不支持
public synchronized void reset() throws IOException {
throw new IOException("mark/reset not supported");
}
// 判断当前流是否支持标记流,和上面两个方法配套使用
public boolean markSupported() {
return false;
}InputStream 子类关系图:
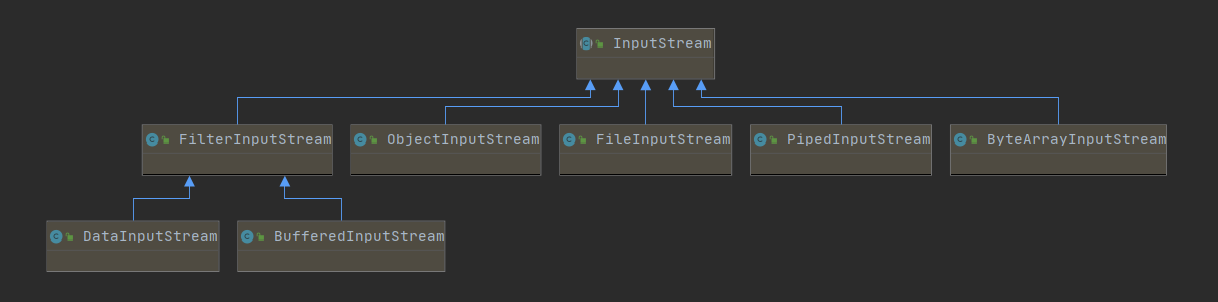
子类介绍:
-
FileInputStreamFileInputStream 从文件系统中的文件中获取输入字节。FileInputStream 用于读取原始字节流,例如图像数据。要读取字符流,请考虑使用 FileReader。
-
ObjectInputStream反序列化之前使用 ObjectOutputStream 编写的原始数据和对象。
-
ByteArrayInputStream内部有一个缓冲区,其中包含可以从流中读取的字节。内部计数器跟踪读取方法提供的下一个字节。关闭 ByteArrayInputStream 没有任何效果。支持设置流中的当前标记位置。
-
PipedInputStream管道输入流,提供写入管道输出流的任何数据字节。通常,数据由一个线程从 PipedInputStream 对象读取,数据由其他线程写入相应的 PipedOutputStream。 不建议尝试从单个线程使用这两个对象,因为这可能会使线程死锁。
-
FilterInputStream可能沿途转换数据或提供附加功能。类 FilterInputStream 本身只是默认使用了 InputStream 的所有方法。 FilterInputStream 的子类可能会进一步覆盖这些方法中的一些,也可能提供额外的方法和字段。
-
BufferedInputStream向另一个输入流添加功能,即缓冲输入和支持标记和重置方法的能力。 创建 BufferedInputStream 时,会创建一个内部缓冲区数组。当读取或跳过流中的字节时,内部缓冲区会根据需要从包含的输入流中重新填充,一次很多字节。 标记操作会记住输入流中的一个点,重置操作会导致在从包含的输入流中获取新字节之前重新读取自最近的标记操作以来读取的所有字节。
-
DataInputStream数据输入流,允许应用程序以独立于机器的方式从底层输入流中读取原始 Java 数据类型。 应用程序使用数据输出流来写入稍后可由数据输入流读取的数据。
-
OutputStream
OutputStream 也是属于抽象类,提供了write方法;
// 抽象方法
// 写入一个字节,可以看到这里的参数是一个 int 类型
// 将一个字节写入输出流,int 类型的 32 位,只有低 8 位才写入,高 24 位将被忽略
public abstract void write(int b) throws IOException;
public void write(byte b[]) throws IOException {
write(b, 0, b.length);
}
// 将 byte 数组从 off 位置开始,len 长度的字节写入
public void write(byte b[], int off, int len) throws IOException {
if (b == null) {
throw new NullPointerException();
} else if ((off < 0) || (off > b.length) || (len < 0) ||
((off + len) > b.length) || ((off + len) < 0)) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return;
}
for (int i = 0 ; i < len ; i++) {
write(b[off + i]);
}
}
public void flush() throws IOException {
}
public void close() throws IOException {
}OutputStream子类关系图:
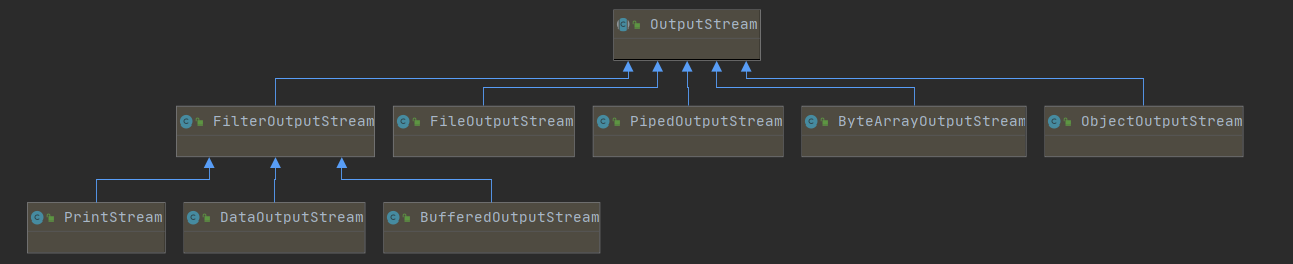
子类介绍:
-
FileOutputStream文件输出流,用于将数据写入 File 或 FileDescriptor 的原始字节输出流,例如图像数据。要写入字符流,请考虑使用 FileWriter。
-
ObjectOutputStreamObjectOutputStream 将 Java 对象的原始数据类型和图形写入 OutputStream。只有支持
java.io.Serializable接口的对象才能写入流。 -
ByteArrayOutputStream实现了一个输出流,其中数据被写入一个字节数组。缓冲区会随着数据写入而自动增长。
-
PipedOutputStream管道输出流可以连接到管道输入流以创建通信管道。管道输出流是管道的发送端。通常,数据由一个线程写入 PipedOutputStream 对象,数据由其他线程从连接的 PipedInputStream 读取。
-
FilterOutputStream是过滤输出流的所有类的超类。-BufferedOutputStream该类实现了一个缓冲输出流。通过设置这样的输出流,应用程序可以将字节写入底层输出流,而不必为写入的每个字节调用底层系统。 - `DataOutputStream` 数据输出流允许应用程序以可移植的方式将原始 Java 数据类型写入输出流。然后,应用程序可以使用数据输入流将数据读回。 - `PrintStream` PrintStream 向另一个输出流添加功能,即方便地打印各种数据值的表示的能力。 PrintWriter 类应该用于需要写入字符而不是字节的情况
Reader
Reader 是一个用于读取字符流的抽象类,并且实现了Readable, Closeable接口。子类必须实现的唯一方法 read(char[], int, int) 和 close()。
// 将字符读入数组的一部分。此方法将阻塞,直到某些输入可用、发生 I/O 错误或到达流的末尾。
abstract public int read(char cbuf[], int off, int len) throws IOException;
// 流关闭,进一步的 read()、ready()、mark()、reset() 或 skip() 调用将抛出 IOException。关闭先前关闭的流没有任何效果。
abstract public void close() throws IOException;大多数子类会覆盖Reader 定义的一些方法,以提供更高的效率、附加功能或两者兼而有之。
Reader 子类关系图:
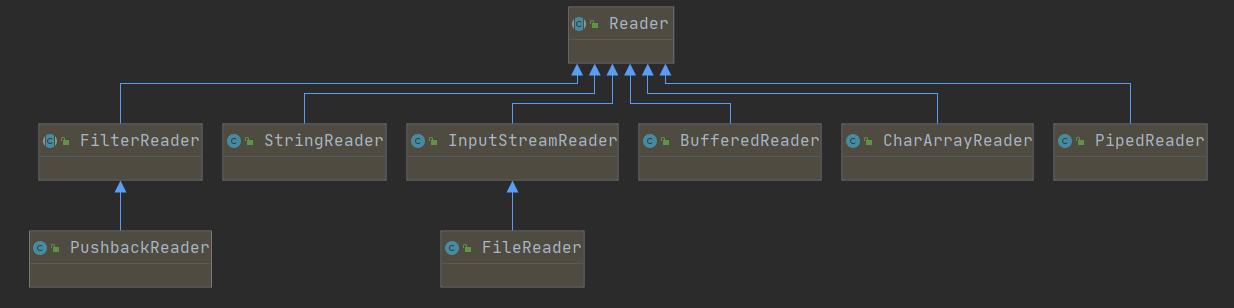
子类介绍:
-
BufferedReader从字符输入流中读取文本,缓冲字符以便有效读取字符、数组和行。 可以指定缓冲区大小,也可以使用默认大小。 -
CharArrayReader实现可用作字符输入流的字符缓冲区。 -
StringReader源是字符串的字符流。 -
PipedReader管道字符输入流。
-
InputStreamReaderInputStreamReader 是从字节流到字符流的桥梁。-FileReader读取字符文件的类。 -
FilterReader用于读取过滤字符流的抽象类。抽象类 FilterReader 本身提供了将所有请求传递给包含的流的默认方法。 FilterReader 的子类应该覆盖其中一些方法,并且还可以提供额外的方法和字段。-PushbackReader字符流读取器,允许将字符推回到流中。
Writer
Reader 是一个用于写入字符流的抽象类,实现了Appendable, Closeable, Flushable接口。
子类必须实现的唯一方法是 write(char[], int, int)、flush() 和 close()。
public abstract class Writer implements Appendable, Closeable, Flushable {
...
abstract public void write(char cbuf[], int off, int len) throws IOException;
abstract public void flush() throws IOException;
abstract public void close() throws IOException;
}Writer子类关系图:
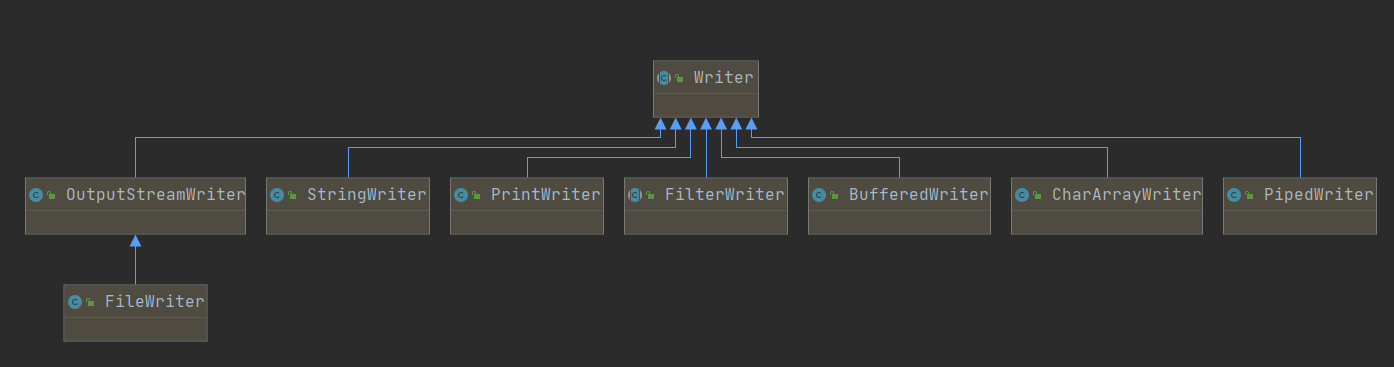
子类介绍:
BufferedWriter将文本写入字符输出流,缓冲字符以提供单个字符、数组和字符串的高效写入。CharArrayWriter此类实现了可用作 Writer 的字符缓冲区。当数据写入流时,缓冲区会自动增长。FilterWriter用于编写过滤字符流的抽象类。PipedWriter管道字符输出流。PrintWriter将对象的格式化表示打印到文本输出流。不抛出 I/O 异常,可以通过调用 checkError() 来查询是否发生了任何错误。StringWriter字符串缓冲区中收集其输出的字符流,然后可用于构造字符串。OutputStreamWriterOutputStreamWriter 是从字符流到字节流的桥梁。-FileWriter用于编写字符文件的类。
IO 模型
Unix 下有五种 I/O 模型:
- 阻塞式 I/O
- 非阻塞式 I/O
- I/O 复用(select 和 poll)
- 信号驱动式 I/O(SIGIO)
- 异步 I/O(AIO)
一个输入操作通常包括两个阶段:
- 等待数据准备好
- 从内核向进程复制数据
对于一个套接字上的输入操作,第一步通常涉及等待数据从网络中到达。当所等待分组到达时,它被复制到内核中的某个缓冲区。第二步就是把数据从内核缓冲区复制到应用进程缓冲区。
阻塞式 I/O
阻塞,顾名思义,当进程在等待数据时,若该数据一直没有产生,则该进程将一直等待,直到等待的数据产生为止,这个过程中进程的状态是阻塞的。
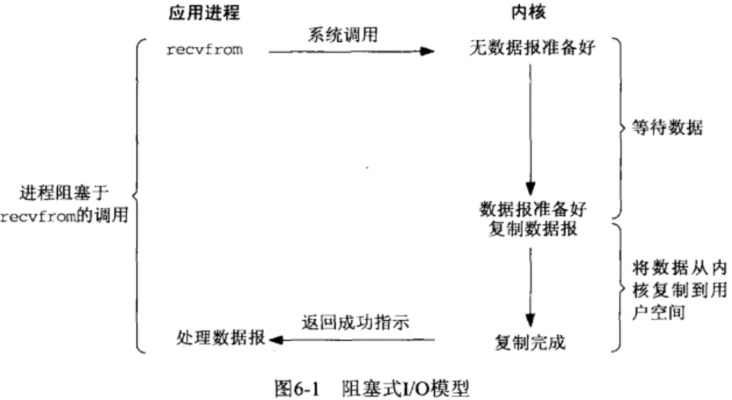
如上图所示,在linux中,用户态进程调用recvfrom系统调用接收数据,当前内核中并没有准备好数据,该用户态进程将一直在此等待,不会进行其他的操作,待内核态准备好数据,将数据从内核态拷贝到用户空间内存,然后recvfrom返回成功的指示,此时用户态进行才解除阻塞的状态,处理收到的数据。
非阻塞式I/O
在非阻塞式I/O模型中,当进程等待内核的数据,而当该数据未到达的时候,进程会不断询问内核,直到内核准备好数据。
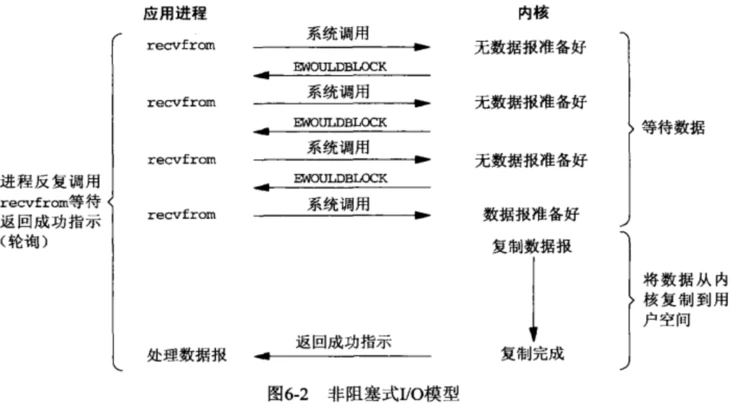
如上图,用户态进程调用recvfrom接收数据,当前并没有数据报文产生,此时recvfrom返回EWOULDBLOCK,用户态进程会一直调用recvfrom询问内核(轮询),待内核准备好数据的时候,之后用户态进程不再询问内核,待数据从内核复制到用户空间,recvfrom成功返回,用户态进程开始处理数据。
数据从内核复制到用户空间中的这一段时间中,用户态进程还是处于阻塞状态的。 与阻塞式模型不同的是,非阻塞相当于进程一直在敲门问“数据好了么,快给我”,然后房门后的人说“没有准备好,请稍后!”,这个过程是一种轮询的状态。
I/O 复用
多路复用,意思就是本来一条链路上一次只能传输一个数据流,如果要实现两个源之间多条数据流同时传输,那就得需要多条链路了,但是复用技术可以通过将一条链路划分频率,或者划分传输的时间,使得一条链路上可以同时传输多条数据流。
套用到I/O复用模型上,可以对应到如下应用场景:如果一个进程需要等到多种不同的消息,那么一般的做法就是开启多条线程,每个线程接收一类消息,如果每个线程都是采用阻塞式I/O模型,那么每个线程在消息未产生的时候就会阻塞,也就是说在多线程中使用阻塞式I/O。
I/O复用就是基于上述的场景中,无需采用多线程监听消息的方式,进程直接监听所有的消息类型,这其中就涉及到select、poll、epoll等不同的方法。
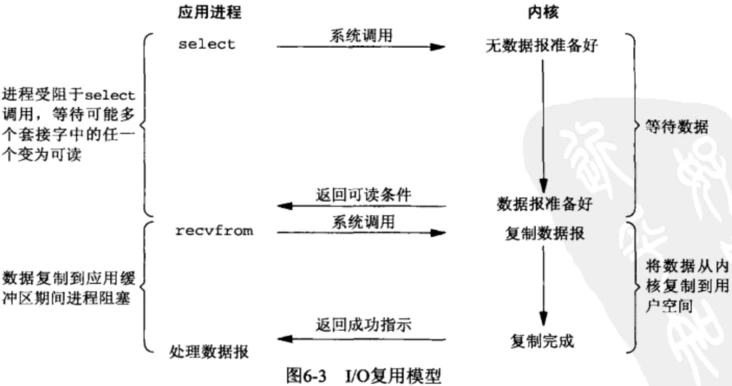
如上图所示,用户态进程采用select或者 poll等待数据,通过select可以等待多个不同类型的消息,如果其中有一个类型的消息准备好,则select会返回信息,然后用户态进程调用recvfrom把数据从内核复制到进程中。
I/O 复用又被称为 Event Driven I/O,即事件驱动 I/O。
如果一个 Web 服务器没有 I/O 复用,那么每一个 Socket 连接都需要创建一个线程去处理。如果同时有几万个连接,那么就需要创建相同数量的线程。并且相比于多进程和多线程技术,I/O 复用不需要进程线程创建和切换的开销,系统开销更小。
I/O复用和阻塞式I/O很相似 不同的是,I/O复用等待多类事件,阻塞式I/O只等待一类事件 另外,在I/O复用中,会产生两个系统调用(如上图,select和recvfrom),而阻塞式I/O只产生一个系统调用。 那么这就涉及到具体的性能问题,当只存在一类事件的时候,使用阻塞式I/O模型的性能会更好,当存在多种不同类型的事件时,I/O复用的性能要好的多,因为阻塞式I/O模型只能监听一类事件,所以这个时候需要使用多线程进行处理。
信号驱动式 I/O
在信号驱动式I/O模型中,与阻塞式和非阻塞式有了一个本质的区别,那就是用户态进程不再等待内核态的数据准备好,直接可以去做别的事情。等待数据阶段应用进程是非阻塞的,但是在将数据从内核复制到用户空间这段时间内用户态进程是阻塞的。
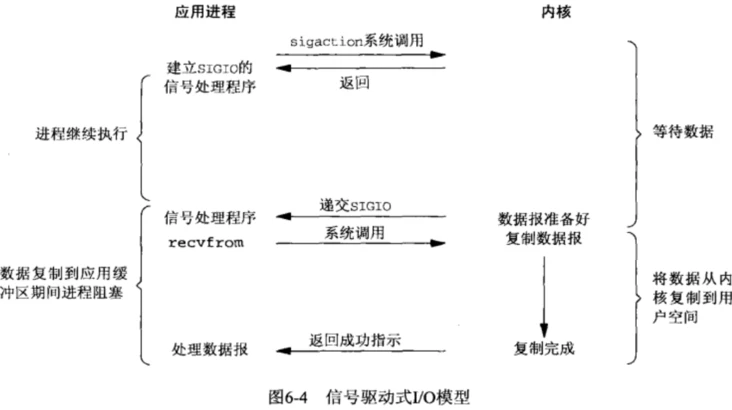
如上图所示,当需要等待数据的时候,首先用户态会向内核发送一个sigaction 信号,告诉内核我要什么数据,然后用户态就不管了,做别的事情去了,而当内核态中的数据准备好之后,内核立马发给用户态一个信号,说”数据准备好了,快来查收“,用户态进程收到之后,立马调用recvfrom,等待数据从内核空间复制到用户空间,待完成之后recvfrom返回成功指示,用户态进程才处理别的事情。
相比于非阻塞式 I/O 的轮询方式,信号驱动 I/O 的 CPU 利用率更高。
异步I/O
异步I/O模型相对于信号驱动式I/O模型就更彻底了,内核会在所有操作完成之后向应用进程发送信号。
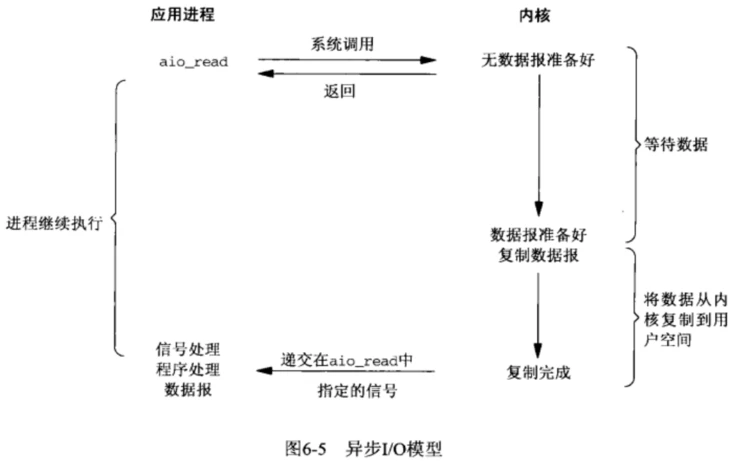
如上图,首先用户态进程告诉内核态需要什么数据(上图中通过aio_read),然后用户态进程就不管了,做别的事情,内核等待用户态需要的数据准备好,然后将数据复制到用户空间,此时才告诉用户态进程,”数据都已经准备好,请查收“,然后用户态进程直接处理用户空间的数据。
在复制数据到用户空间这个时间段内,用户态进程也是不阻塞的。
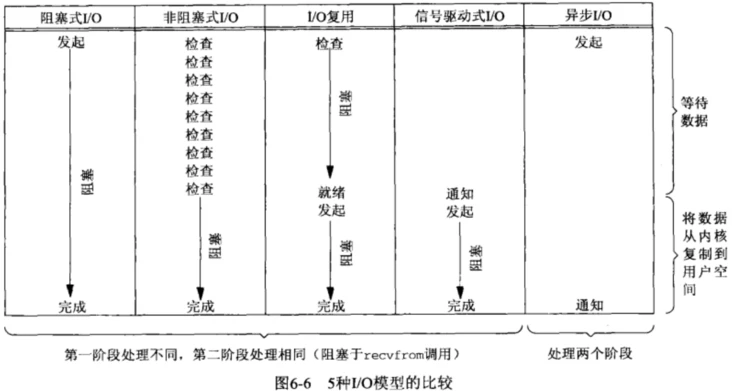
I/O 模型比较
同步 I/O 与异步 I/O:
- 同步 I/O:应用进程在调用
recvfrom操作时会阻塞。 - 异步 I/O:不会阻塞。
阻塞式 I/O、非阻塞式 I/O、I/O 复用和信号驱动 I/O 都是同步 I/O。
虽然非阻塞式 I/O 和信号驱动 I/O 在等待数据阶段不会阻塞,但是在之后的将数据从内核复制到应用进程这个操作会阻塞。
Java NIO零拷贝
零拷贝(Zero-copy)
零复制(英语:Zero-copy;也译零拷贝)技术是指计算机执行操作时,CPU不需要先将数据从某处内存复制到另一个特定区域。这种技术通常用于通过网络传输文件时节省CPU周期和内存带宽。 ——维基百科-零复制
零拷贝的作用是在数据报从网络设备到用户程序空间传递的过程中,减少数据拷贝次数,减少系统调用,实现 CPU 的零参与,彻底消除 CPU 在这方面的负载。
实现零拷贝用到的最主要技术是 DMA 数据传输技术和内存区域映射技术。
- 零拷贝机制可以减少数据在内核缓冲区和用户进程缓冲区之间反复的 I/O 拷贝操作。
- 零拷贝机制可以减少用户进程地址空间和内核地址空间之间因为上下文切换而带来的 CPU 开销。
在 Java NIO 中的通道(Channel)就相当于操作系统的内核空间(kernel space)的缓冲区,而缓冲区(Buffer)对应的相当于操作系统的用户空间(user space)中的用户缓冲区(user buffer)。
1.MappedByteBuffer
MappedByteBuffer 是 NIO 基于内存映射(mmap)这种零拷贝方式的提供的一种实现,它继承自 ByteBuffer,其内容是文件的内存映射区域。
FileChannel 定义了一个 map() 方法,它可以把一个文件从 position 位置开始的 size 大小的区域映射为内存映像文件。
public abstract MappedByteBuffer map(MapMode mode, long position, long size)
throws IOException;mode:限定内存映射区域(MappedByteBuffer)对内存映像文件的访问模式,包括只可读(READ_ONLY)、可读可写(READ_WRITE)和写时拷贝(PRIVATE)三种模式。position:文件映射的起始地址,对应内存映射区域(MappedByteBuffer)的首地址。size:文件映射的字节长度,从 position 往后的字节数,对应内存映射区域(MappedByteBuffer)的大小。
MappedByteBuffer相比 ByteBuffer 新增了 fore()、load() 和 isLoad()三个重要的方法:
fore():对于处于READ_WRITE模式下的缓冲区,把对缓冲区内容的修改强制刷新到本地文件。load():将缓冲区的内容载入物理内存中,并返回这个缓冲区的引用。isLoaded():如果缓冲区的内容在物理内存中,则返回 true,否则返回 false。
MappedByteBuffer 的特点和不足:
- MappedByteBuffer 使用是堆外的虚拟内存,因此分配(map)的内存大小不受 JVM 的 -Xmx 参数限制,但是也是有大小限制的。 如果当文件超出 Integer.MAX_VALUE 字节限制时,可以通过 position 参数重新 map 文件后面的内容。
- MappedByteBuffer 在处理大文件时性能的确很高,但也存内存占用、文件关闭不确定等问题,被其打开的文件只有在垃圾回收的才会被关闭,而且这个时间点是不确定的。
- MappedByteBuffer 提供了文件映射内存的 mmap() 方法,也提供了释放映射内存的 unmap() 方法。然而 unmap() 是 FileChannelImpl 中的私有方法,无法直接显示调用。因此,用户程序需要通过 Java 反射的调用 sun.misc.Cleaner 类的 clean() 方法手动释放映射占用的内存区域。
2.DirectByteBuffer
DirectByteBuffer 和零拷贝有什么关系?
DirectByteBuffer 继承值MappedByteBuffer,属于是 MappedByteBuffer 的具体实现类,因此除了允许分配操作系统的直接内存以外,DirectByteBuffer 本身也是具有文件内存映射的功能的。
DirectByteBuffer 的对象引用位于 Java 内存模型的堆里面,JVM 可以对 DirectByteBuffer 的对象进行内存分配和回收管理,一般使用 DirectByteBuffer 的静态方法 allocateDirect() 创建 DirectByteBuffer 实例并分配内存。
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}DirectByteBuffer 内部的字节缓冲区位在于堆外的(用户态)直接内存,它是通过 Unsafe 的本地方法 allocateMemory() 进行内存分配,底层调用的是操作系统的 malloc() 函数。
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
base = unsafe.allocateMemory(size); // UNSAFE.allocateMemory分配内存
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
// 清洁工线程
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}初始化 DirectByteBuffer 时还会创建一个 Deallocator 线程,并通过 Cleaner 的 freeMemory() 方法来对直接内存进行回收操作,freeMemory() 底层调用的是操作系统的 free() 函数。
private static class Deallocator implements Runnable
{
private static Unsafe unsafe = Unsafe.getUnsafe();
private long address;
private long size;
private int capacity;
private Deallocator(long address, long size, int capacity) {
assert (address != 0);
this.address = address;
this.size = size;
this.capacity = capacity;
}
public void run() {
if (address == 0) {
// Paranoia
return;
}
unsafe.freeMemory(address); // freeMemory() 底层调用的是操作系统的 free() 函数。
address = 0;
Bits.unreserveMemory(size, capacity);
}
}DirectByteBuffer 在 MappedByteBuffer 的基础上还提供了内存映像文件的随机读取 get() 和写入 write() 的操作。
public byte get() {
return ((unsafe.getByte(ix(nextGetIndex()))));
}
public byte get(int i) {
return ((unsafe.getByte(ix(checkIndex(i)))));
}
public ByteBuffer put(byte x) {
unsafe.putByte(ix(nextPutIndex()), ((x)));
return this;
}
public ByteBuffer put(int i, byte x) {
unsafe.putByte(ix(checkIndex(i)), ((x)));
return this;
}3.FileChannel
FileChannel 是一个用于文件读写、映射和操作的通道,同时它在并发环境下是线程安全的,基于 FileInputStream、FileOutputStream或者 RandomAccessFile的 getChannel() 方法可以创建并打开一个文件通道。
FileChannel 定义了 transferFrom() 和 transferTo() 两个抽象方法,它通过在通道和通道之间建立连接实现数据传输的。
FileChannel的transferTo()、transferFrom()方法也可以支持零复制(如果底层操作系统支持)。
transferTo() 和 transferFrom() 底层都是基于 sendfile 实现数据传输的。
其中FileChannel的实现类FileChannelImpl.java 定义了 3 个常量,用于标示当前操作系统的内核是否支持 sendfile 以及 sendfile 的相关特性。
private static volatile boolean transferSupported = true;
private static volatile boolean pipeSupported = true;
private static volatile boolean fileSupported = true;transferSupported:用于标记当前的系统内核是否支持 sendfile() 调用,默认为 true。pipeSupported:用于标记当前的系统内核是否支持文件描述符(fd)基于管道(pipe)的 sendfile() 调用,默认为 true。fileSupported:用于标记当前的系统内核是否支持文件描述符(fd)基于文件(file)的 sendfile() 调用,默认为 true。
以 transferTo() 的源码实现为例。
FileChannelImpl 首先执行 transferToDirectly() 方法,以 sendfile 的零拷贝方式尝试数据拷贝。如果系统内核不支持 sendfile,进一步执行 transferToTrustedChannel() 方法,以 mmap的零拷贝方式进行内存映射,这种情况下目的通道必须是 FileChannelImpl 或者 SelChImpl 类型。
如果以上两步都失败了,则执行 transferToArbitraryChannel() 方法,基于传统的 I/O 方式完成读写。
public long transferTo(long var1, long var3, WritableByteChannel var5) throws IOException {
this.ensureOpen();
if (!var5.isOpen()) {
throw new ClosedChannelException();
} else if (!this.readable) {
throw new NonReadableChannelException();
} else if (var5 instanceof FileChannelImpl && !((FileChannelImpl)var5).writable) {
throw new NonWritableChannelException();
} else if (var1 >= 0L && var3 >= 0L) {
long var6 = this.size();
if (var1 > var6) {
return 0L;
} else {
int var8 = (int)Math.min(var3, 2147483647L);
if (var6 - var1 < (long)var8) {
var8 = (int)(var6 - var1);
}
long var9;
// 1.执行 transferToDirectly() 方法,以 sendfile 的零拷贝方式尝试数据拷贝
if ((var9 = this.transferToDirectly(var1, var8, var5)) >= 0L) {
return var9;
} else {
// 2. sendFile失败
return (var9 = this.transferToTrustedChannel(var1, (long)var8, var5)) >= 0L ? var9 : this.transferToArbitraryChannel(var1, var8, var5);
}
}
} else {
throw new IllegalArgumentException();
}
}